
问题描述
Qwen简介
Qwen是由阿里云开发的一系列大型语言模型(LLMs),旨在满足多样化的自然语言处理需求。
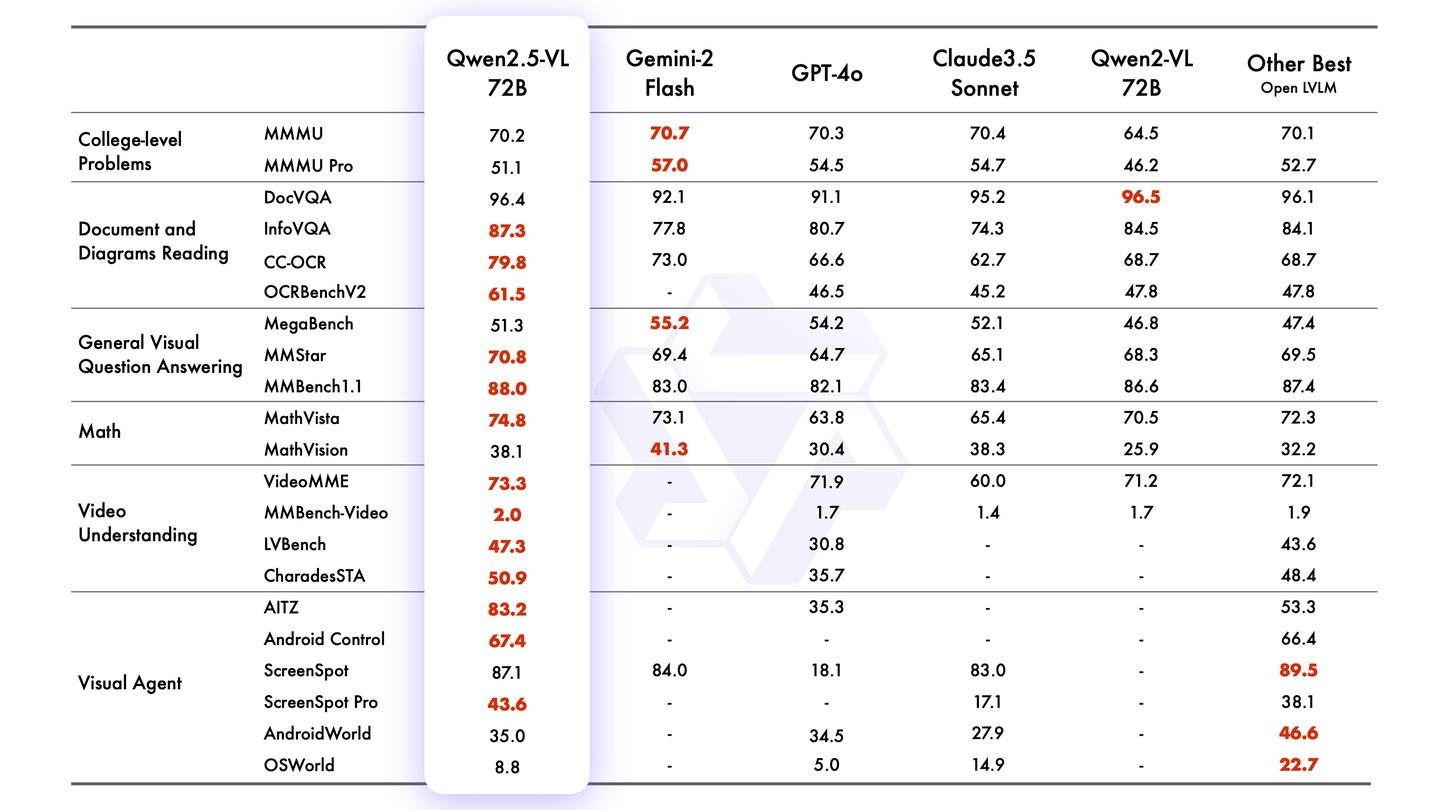
昨晚发布的Qwen2.5-VL,全面领先GPT-4o
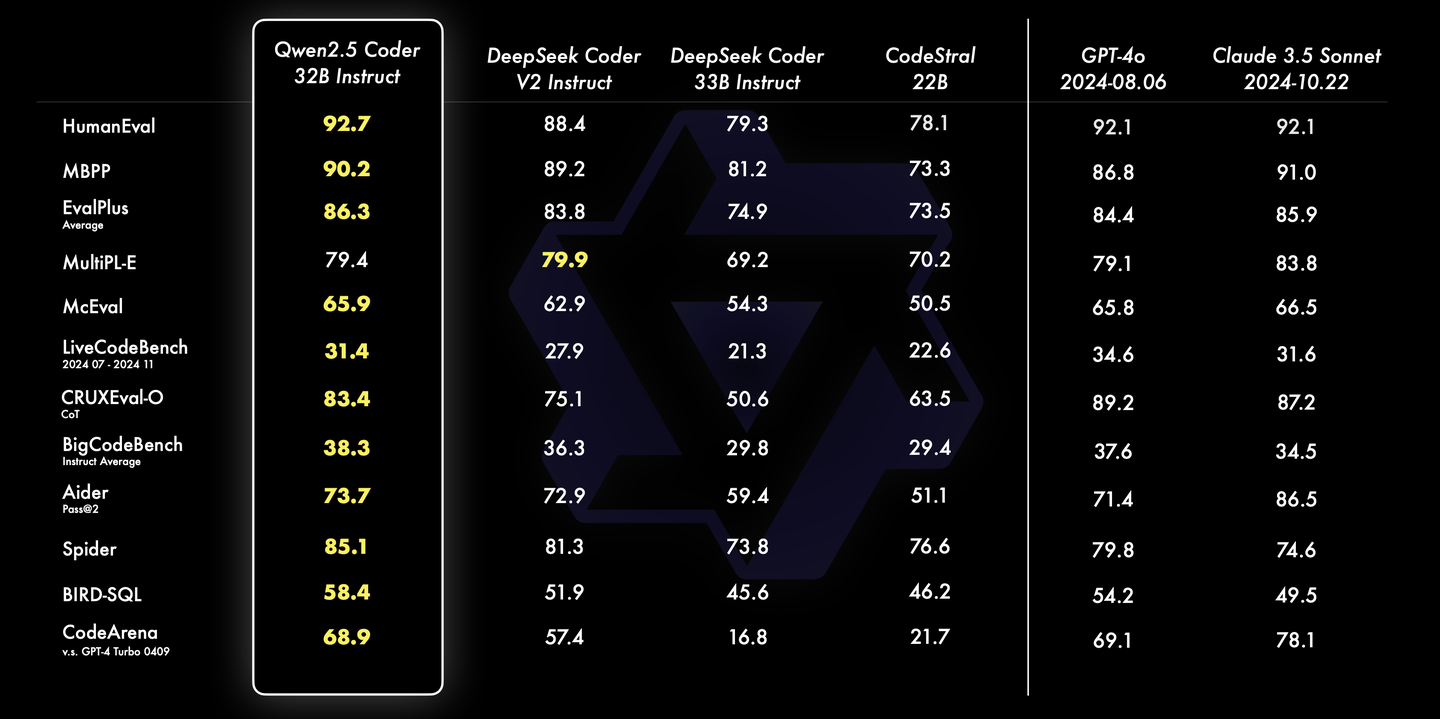
此前发布的Qwen2.5-Coder-32B-Instruct能超越更大规模的DeepSeek Coder V2
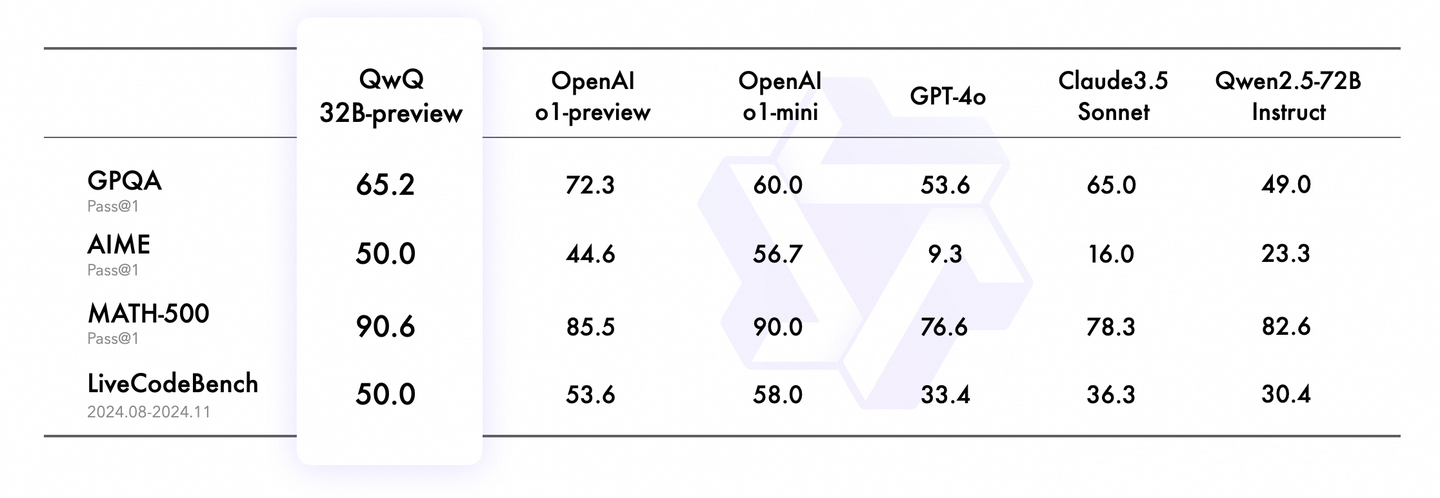
还有首款开源推理模型QWQ
常年写sft/RL Qwen和DeepSeek训练脚本和优化,算法同事就是爬数据and跑训练。
Qwen靠美金就可以,并不是靠技术创新(看模型结构基本没咋变,和llama比难有优势),而且结果只是打榜,经不住真实用户拷打,R1是能经受美国佬的考验,且把NV股价干掉18%,折合好几个阿里巴巴,都不用吹,另外Deepseek目前160多个国家 appstore top1,且歪果仁在X上一片好评,如果对手都不吝赞美(meta、微软、sd老板都明确肯定ds的创新,anthropic ceo怂恿更严格芯片封锁),那真的可以openai平起平坐(恰巧Sam Altman也confirm了r1的强大,这应该是头一次,其他公司没这个机会),成本上吊打closed ai没啥悬念,人头担保。
V3的infra冠绝全球,虽然训练没有降1/10(这个是外行的认知),但训练MFU确实加速了50%左右(moe 256 expert MFU达到45%,比dense模型难),同时用fp8还很顺利;更重要的是推理decoding phase几乎快做成compute bound,几乎秒杀任何team……v3报告一出来,前前后后分析了一周,mla、mtp、dualpipe及overlap、fp8 train、分布式推理,每一项我很有成效且价值巨大,所以就给了全球top1的肯定,参考我之前写的文章(对了,之前我对他们卡间机间带宽估算提出质疑,然后最近在我的文章下面抓到v3 paper作者之一,400gb ib网卡,nccl他们能跑到50GB/s,真的难以置信),不接受反驳……paper透露的深度和聪明感觉同cuda一样,一旦机会来了,他们肯定会有位置……
R1直接打破了推理scaling这个错误方向(个人认为,其实开源o1都是靠多次采样和搜索,并且通过prm进行verify,如果模型能力没显著提升价值就不大,成本就不说了),真正让模型有reason能力,同时成本降低很多,让我等屌丝都能用,而openai 200刀基本是笑话。其独创的GRPO降低ppo训练成本的同时保证算法可靠性,Qwen是效法者。
Qwen靠什么呢, 现状是,大部分算法都在折腾数据,post train基本都做sft,RL玩的都很浅(不做优化,相比sft慢10倍),训练基本做不了任何优化,因为试错成本太高且水平不够。
ps:评论区多了很多无脑黑ds的言论,特别没有任何理由的,什么蒸馏、套壳理论,看到了就直接开喷了,不多废话,这里不适合你。