
问题描述
运行环境:win32解释内容:
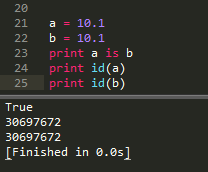
a = 1.1
b = 1.1
print id(a)
print id(b)
问题描述:
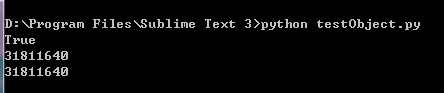
测试两个float值创建时是否引用同一个对象,在sublime中直接解释python时发现 a is b = True,但是在python idle中,a is b #=>False,一开始以为是sublime的问题,并且在sublime的安装路径中发现了python3.3,以为是sublime调用了python3(python3中是否是这样的结果呢?没有试过)。但是当我把sublime中的python解释器改成系统安装的python2.7之后,结果仍然是a is b = True,然后我又认为是sublime自己修改了某些内容,就到cmd,按照sublime的解释命令,输入python test.py运行,结果:a is b = True。
问题:
python一条一条地解释和用python命令直接解释的过程有什么区别?
附件:
1.sublime运行结果
4 python版本全部一致:


题主想的“逐行解释”与“整体解释”的差异的思路是对的,不过细节不太对。下面讲点细节。
跟Sublime、IDLE啥的没关系。
$ python
Python 2.7.5 (default, Mar 9 2014, 22:15:05)
[GCC 4.2.1 Compatible Apple LLVM 5.0 (clang-500.0.68)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
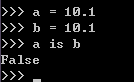
>>> a = 10.1
>>> b = 10.1
>>> a is b
False
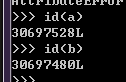
>>> id(a)
140475784803760
>>> id(b)
140475784803736
>>> (10.1) is (10.1)
True
>>> def foo():
... a = 10.1
... b = 10.1
... return a is b
...
>>> foo()
True题主可以试试在所有题主用的CPython环境里执行下面的代码:
def foo():
a = 10.1
b = 10.1
return a is b
print(foo())而结果总是True。
然后再试试:
def bar():
return 10.1
def quux():
return 10.1
print(bar() is quux())
而结果总是False。
<- 看看是否如此?
这是跟CPython的编译单元以及常量池处理有关的。
================================================
背景知识
CPython的代码的“编译单元”是函数——每个函数单独编译,得到的结果是一个PyFunctionObject对象,其中带有字节码、常量池等各种信息。Python的顶层代码也被看作一个函数。
函数之间有嵌套时,外层函数的代码并不包含内层函数的代码,而只是包含创建出内层函数的函数对象(PyFunctionObject)的逻辑。
让我们看看上面的foo()函数的字节码(通过dis.dis(foo)获取):
>>> dis.dis(foo)
2 0 LOAD_CONST 1 (10.1)
3 STORE_FAST 0 (a)
3 6 LOAD_CONST 1 (10.1)
9 STORE_FAST 1 (b)
4 12 LOAD_FAST 0 (a)
15 LOAD_FAST 1 (b)
18 COMPARE_OP 8 (is)
21 RETURN_VALUE
可见a和b的赋值都是由同一个常量池项获得的:LOAD_CONST 1
这条字节码指令的意思是:从当前PyFunctionObject的co_const字段所指向的常量池里,取出下标为1的项,压到操作数栈的栈顶。
每个PyFunctionObject有一个独立的常量池;换句话说,每个PyFunctionObject的co_const字段都指向自己专有的一个常量池对象,而里面的常量池项也是自己专有的。
在同一个编译单元(PyFunctionObject)里出现的值相同的常量,只会在常量池里出现一份,一定会对应到运行时的同一个对象。所以在foo()的例子里,a和b都从同一个常量池项获取值;
在不同的编译单元里,值相同的常量不一定会对应到运行时的同一个对象,要看具体的类型是否自带了某种interning / caching机制(例如Python 2.x系的PyInt / Python 3.x系的PyLong的小整数缓存机制)。
PyFloatObject没有“小数字缓存”机制,所以每次“创建”一个对象(例如PyFloat_FromString() / PyFloat_FromDouble())都一定会得到一个新的对象——id不同、is运算符比较为False。
================================================
“逐行解释”?
其实在CPython的交互式解释器(例如python命令不指定参数时)里,每输入一行可以立即执行的代码,Python就会把它当作一个编译单元来编译到字节码并解释执行;如果输入的代码尚未构成一个完整的单元,例如函数声明或者类声明,则等到获得了完整单元的输入后再当作一个编译单元来处理。
所以当我们在CPython的交互式解释器中分别输入"a = 10.1"、"b = 10.1"这两行时,它们分别被当作一个编译单元处理,其中的常量池没有共享,常量池项也都是各自新创建的,所以会得到a is b为False的结果。
而在同一环境里输入"(10.1) is (10.1)"时,这一行被看作一个编译单元,其中两次对10.1这个常量的使用都变成了对同一对象的引用,因而is的结果为True。
当使用python命令去整体解释一个Python源码文件时,其中位于顶层的
a = 10.1
b = 10.1两行代码就会处于同一个编译单元中,因而共享常量池,因而a is b就会是True。
就这样嗯。本来对这种应该是值语义的对象就不应该关注其identity,不然“乐趣多多”…