
问题描述
先看图片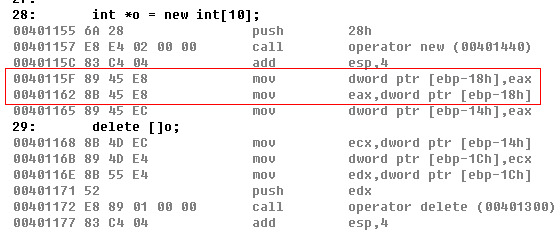
请注意矩形内的代码,它们的作用是——把eax移动到【ebp-18h】这个位置,然后从【ebp-18h】取出数据赋值给eax。。。可是,这样做并没有卵用啊,紧跟着的那句代码还不是把eax赋值给【ebp-14h】了,为什么刚开始不直接这样做呢??
下面这个图片是回复Milo Yip大侠的回答:
其实只需要比较入门的编译原理知识就可以清晰的读懂题主贴出的代码。
题主贴出来的代码展现了Visual C++ 6采用了下述代码生成策略。
首先,所有源码中的运算,包括load/store,都会在
IR层面生成出临时变量。
这是编译器里很常见的中间代码生成策略,好处是让前端逻辑非常简单且一致,而由其产生的冗余可以轻易在后续优化中消除。
所以题主原本贴的代码:
int *o = new int[10];
delete []o;
在编译器内的IR层面生成出了这样的IR:
// int *o = new int[10];
tmp0 = new int[10]; // operation: produce new pointer
int *o = tmp0; // operation: store to local variable
// delete []o;
tmp1 = o; // operation: load from local variable
delete []tmp1; // operation: array delete
然后,由于Visual C++在debug模式几乎禁用了所有优化,所以本来用于消除IR中的冗余的优化都没做。
而用release模式编译的话,Visual C++可以采用copy propagation(复写传播)来消除掉这段代码里的临时变量。
接下来,Visual C++在debug模式下也不做任何实质上的寄存器分配;所有用户声明的变量和编译器内部生成的临时变量都在栈帧上分配了slot,都在内存里。
而用release模式编译的话,变量会尽可能被分配到寄存器里,大幅减少这种内存-寄存器-内存之间的拷贝。
最后,生成最终的机器码时,数据就在这些内存里的栈帧的slot之间移动。由于x86的运算和数据移动指令都不接受两个操作数都在内存里,所以必须借助临时寄存器来完成实际运算。
所以最终生成的代码就是这样:
// stack frame layout:
// esp: stack pointer
// ebp: frame pointer
//
// [ebp - 1ch]: tmp1
// [ebp - 18h]: tmp0
// [ebp - 14h]: o (local slot)
// [ebp - 10h]: local slot
// [ebp - ch] : local slot
// [ebp - 8h] : local slot
// [ebp - 4h] : local slot
// [ebp + 0h] : saved caller frame pointer
// [ebp + 4h] : return address
// [ebp + 8h] : arg0
// [ebp + ch] : arg1
// [ebp + ...]: arg ...
// int *o = new int[10];
push 28h // arg 0 to operator new; 0x28 == 40 == sizeof(int)*10 == sizeof(int[10])
call operator new[] // return value in eax
add esp, 4 // balance the stack (cdecl)
mov [ebp - 18h], eax // tmp0 = new int[10]
mov eax, [ebp - 18h]
mov [ebp - 14h], eax // o = tmp0
// delete []o
mov ecx, [ebp - 14h]
mov [ebp - 1ch], ecx // tmp1 = o
mov edx, [ebp - 1ch]
push edx // arg 0 to operator delete[]
call operator delete[]
add esp, 4 // balance the stack (cdecl)(栈帧布局的一些细节取决于编译参数,例如是否使用了SEH)
就这样嗯。