
问题描述
编译系统透视:图解编译原理 (豆瓣)似乎是新出的一本编译原理的书,在书店看了下似乎插图很多,不知道是否适合做编译原理入门用的书?
简介:
本书是编译原理领域的鸿篇巨著,中文版尚未出版,英文版权已经输出到了美国。本书的出版将在世界范围内产生重要影响。从以下多个角度讲,本书都具有重要的里程碑意义:
● 它第一次让编译原理不再像是一门高深晦涩的“数学课”,而是一个可以调试、可以接触、可以真切感受的理论体系。本书用1140 余幅信息量巨大的运行时结构图和视频动画取代了同类书中复杂枯燥的数学公式,更加立体和直观,生动地将编译后的执行程序在内存中的运行时结构图展现了出来。
● 它第一次将 GCC 源代码、编译原理、运行时结构、编译系统原理(包含汇编与链接)的内在关系、逻辑与原理梳理清楚了,并将它们结合成一个整体,真正能够让读者透彻掌握编译器如何运行、如何设计,以及为什么要这么设计。
● 它是第一本系统解读著名商用编译器 GCC 核心源代码的著作。 GCC 源代码一共有 600 万行,为了便于讲解和阅读,本书进行了取舍和裁剪,讲解了与编译本质相关的、最核心的 60 万行代码。
全书一共 8 章,具体内容和逻辑如下:
第 1 章以一个 C 程序(先简单,后复杂)的运行时结构为依托,对程序编译的整体过程做了宏观讲述,让读者对编译有一个整体认识,这样更容易理解后面的内容。
第 2 ~ 6 章通过实际的程序案例、结合 GCC 的源代码,根据程序编译的顺序和流程,依次讲解了词法分析、语法分析、中间结构和目标代码的生成,遵循了由易到难的原则,先是通过简单程序讲解清楚原理,然后通过复杂程序强化理解。
第 7 章讲解了与编译器紧密关联的汇编器和链接器,让读者对可执行程序的最终生成有一个完整的了解。
第 8 章讲解了预处理,就编译器的执行顺序而言,预处理器的执行比较靠前,之所以放在最后讲,是因为它比较独立,在读者已经了解整个编译过程之后再讲解,读者会更容易理解。
谢邀。题主说的是才出不久的《编译系统透视:图解编译原理》一书。
豆瓣链接:
《编译系统透视:图解编译原理》华章图书链接:
华章图书 - 编译系统透视:图解编译原理样章:
编译系统透视:图解编译原理 - IT168配套视频:
《编译系统透视》配套视频配套源码:即将(也就是尚未)公开链接(注意!!!)。我看到公开链接的消息的话会更新过来。
总体印象
看到这个问题才知道新出了这么一本书,聊有兴致地看了下目录然后读了一下样章(头3章),觉得挺不错。还没取找配套的视频来看。
已经托人帮忙带一本过来,等拿到实体书读过之后再看看有没有什么要更新到这个回答的。
一句话:杨福川编辑又立功了 >_<
这是一本以GCC的源码剖析为题的入门书。它以GCC的源码为线索,对C语言的非优化编译的整个编译流程,包括编译后的链接以及运行时结构都有图文并茂的讲解;着重讲解了GCC的语法分析部分。
说真的还挺震撼:敢拿产品级C语言编译器为主题来做源码剖析,写作团队还是很够魄力的。本书有配套的裁剪版GCC 4.x系列的源码,并且带有配套的编译和调试环境,这点是最最吸引的地方;然而目前配套的裁剪后源码尚未公开,配套的调试环境似乎只是在作者之一的杨老师授课时给学生使用了。源码剖析类的书就应该方便读者能动手调试实际运行中的程序,这点是这本书的强项。
本书在图解方面做得确实很不错。许多细节步骤都有配图,特别是介绍语法分析的部分讲解得很详细,方便读者形象的理解每个步骤发生的变化。不过,就如书中前言所说,这些“动态”的图解恐怕以动态图片或者视频的方式来展示效果会更好,而本书的头三章也有配套视频(链接在本回答开头)。
它不是,注意不是,一本深入讲解编译“原理”的书。它并不深入介绍词法分析或语法分析背后的理论,而是简单带过一点理论之后以若干案例配合图解,结合GCC的具体实现来讲解C编译器的情况。
这意味着:这本书会贴很多带注释的GCC源码;这本书也会有很多步骤分得很细的图解——对一些读者来说这些图可能过于冗长了。不喜欢这种风格的源码剖析书的同学请不要购买这本书,毕竟不是啥便宜的书orz
这本书的贴代码和图解风格,请参考
如何评价《编译系统透视:图解编译原理》一书? - 德玛西亚的回答购买前请一定要读读样章感受一下这是否是合适您的阅读习惯的书。样章链接在本回答顶上。
我原本的回答似乎引起了一些对这本书不正确的期待,请参考
如何评价《编译系统透视:图解编译原理》一书? - 赵跃宇的回答如果您跟引用的这个回答有相同期望的话请不要购买这本书嗯。我得想想怎么组织语言才不容易引起误解。
=======================================================
头重脚轻
然而…嗯当然得有然而。
然而这本书跟许多定位在入门级别的编译原理书一样,“头重脚轻”,说得不好听有点虎头蛇尾;词法与语法分析占的篇幅实在太多,而对产品级C语言编译器中真正的重头戏——编译优化——只有寥寥几笔简单带过。有选题GCC的魄力,却没有把握GCC精华的结果,相当可惜。
其它定位在入门级编译原理的书籍,通常搭配的是比较简单的实现,例如本回答最后提到的LCC和cbc;对于比较简单的实现把主要篇幅放在编译器前端是很合适的,因为对应的实现中的大头也是在这里。而GCC的大头都是在优化器和后端里,相信会有不少读者是期待着了解更多跟“优化”相关的话题,而这本书偏偏没有侧重于这方面。
当然,定位如此,倒也就是这样了。如此安排对刚接触编译器(特别是GCC)的读者来说应该是比较友好的吧,嗯。
GCC中C语言的编译器的工作流程大致可以分为:(这里特意把前端阶段拆分开来说)
输入源码 -> [ 1. 预处理 libcpp ] -> 预处理后的源码
-> [ 2. 词法分析 c-lex.c ] -> token流
前端 -> [ 3. 语法分析 c-parse.c ] -> AST(GENERIC形式)
-> [ 4. 语义分析 c-typeck.c等 ] -> AST(GENERIC形式)
-------- -> [ 5. 平台无关中间代码生成 Gimplify ] -> IL(GIMPLE形式+CFG)
-> [ 6. 平台无关优化 ] -> IL(GIMPLE形式+CFG)
-> [ 7. 平台相关中间代码生成 ] -> RTL
中端/后端 -> [ 8. 平台相关优化 ] -> RTL
-> [ 9. 目标代码生成 ] -> 汇编 / 机器码
-> [ 10. 链接 ] -> 可执行文件 / 共享库文件GCC里中端/后端都是重量级的,相比之下前端的代码“轻量”得多。
本书绝大部分篇幅都是针对上面的2、3、4和1,有少量篇幅提到5、7、9、10,而6、8都是草草带过。当然,就算不做任何优化也算是走完了整个编译流程,但如果是这样为啥要用前端代码出名的混乱的GCC为案例来分析呢?
同样是对产品级C编译器做源码剖析,要是这本书是用Clang为题感觉或许会更好。反正这本书也没怎么介绍GCC的优化,还不如以代码结构更加干净清晰的Clang入手,把前端部分介绍好,然后简单带过一下LLVM,把LLVM IR、FastISel、Fast寄存器分配和从MachineInstr到目标代码这个最简单的流程介绍一下,书的结构还是会跟现在的保持一致,但内容上或许更易于让读者理解。
如果这本书能做成系列书,出个“第二册”“第三册”,图解一下GCC里的各种优化,那就更好了。把High GIMPLE -> Low GIMPLE,GIMPLE的Tree SSA形式的生成算法,Memory SSA的计算,各种平台无关优化(特别是例如循环优化、指针分析),然后MD文件与BURS,到RTL,到局部和全局图着色寄存器分配,到最终的代码生成,这么一套下来都以这本书对语法分析的详细程度来写出来,那得多赞呐 ^_^
=======================================================
一些细节
节选样章里的一些地方吐点槽:
第一章,第3页:
程序执行的本质就是代码区的指令不断执行,驱使动态数据区和静态数据区产生数据变化。这一过程需要 计算机的管控。下面我们着重介绍对代码区和动态数据区的管控。CPU 中有三个寄存器,分别是 eip、ebp 和 esp,情景如图 1-6 所示。
这段话其实挺突兀的。我在样章中根本搜不到“x86”的字样,前言、第一章等介绍背景的地方都没有提及本书是以x86平台为例子,然而这里却突然冒出了32位x86的三个寄存器的名字。至少把背景定位清楚也好。
-----------------------------------------
第一章,第7页
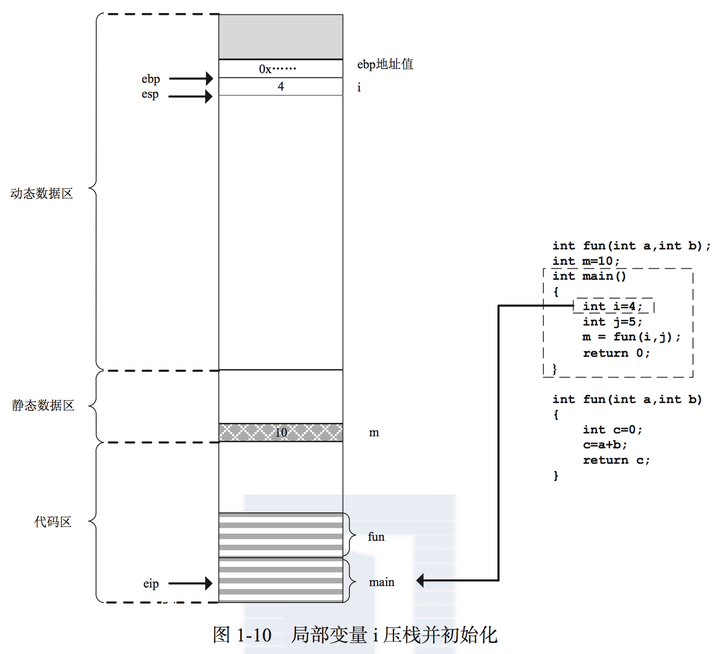
代码例子:
int fun(int a, int b);
int m = 10;
int main() {
int i = 4;
int j = 5;
m = fun(i, j);
return 0;
}
int fun(int a, int b) {
int c = 0;
c = a + b;
return c;
}
这里以GCC为例,在32位x86上用-O0关闭所有优化来编译范例代码,得到的汇编会是:
m:
.long 10
main:
pushl %ebp
movl %esp, %ebp
andl $-16, %esp
subl $32, %esp
movl $4, 28(%esp)
movl $5, 24(%esp)
movl 24(%esp), %eax
movl %eax, 4(%esp)
movl 28(%esp), %eax
movl %eax, (%esp)
call fun(int, int)
movl %eax, m
movl $0, %eax
leave
ret
fun(int, int):
pushl %ebp
movl %esp, %ebp
subl $16, %esp
movl $0, -4(%ebp)
movl 12(%ebp), %eax
movl 8(%ebp), %edx
leal (%edx,%eax), %eax
movl %eax, -4(%ebp)
movl -4(%ebp), %eax
leave
ret
可以看到GCC在这种配置下在进入一个函数时是一口气把整个栈帧的空间都分配好了,例如main()里的:
subl $32, %esp
然后局部变量赋值时不是逐个push到栈上,而是直接在已经分配好的栈帧里赋值到对应的slot上,例如i的赋值:
movl $4, 28(%esp)
可以理解作者只是想以一个笼统的运行时模型来介绍程序运行的大致概念。书中的这组例子也是一种可能的实现方式。但既然以GCC为例,更贴合GCC的做法来讲解是不是更好呢?
-----------------------------------------
目录里有这么一处看着很奇怪的地方:
- 6.7 所有案例语法树转中间结构(RTL)的过程 754
- 6.7.1 基础类型数据语法树转高端gimple的过程 754
- 6.7.2 用户自定义数据语法树转高端gimple的过程 794
- 6.7.3 指针类型数据语法树转高端gimple的过程 838
- 6.7.4 作用域和生存期案例语法树转高端gimple的过程 878
- 6.7.5 复杂表达式案例的语法树转高端gimple的过程 887
章节的大标题是说从语法树生成RTL的过程,但下面的每个小章节的标题都是从语法树到High GIMPLE的过程。
从High GIMPLE到RTL,中间还隔着High GIMPLE -> Low GIMPLE -> CFG -> Tree SSA (可跳过) -> RTL这样的流程。没拿到书不知道这里实际内容怎样,想拜托有读到这部分的同学告知这里实际是怎样的。
=======================================================
其它选择
如上文所述,要覆盖一个从预处理->词法分析->语法分析+语义分析->中间代码生成->汇编->链接这样完整的编译流程,并不需要使用GCC这么重量级的编译器为题。
相比之下,入门用的、介绍C或类C语言编译器的书,我还是更喜欢下面两本书:
- 《A Retargetable C Compiler: Design and Implementation》
- 『ふつうのコンパイラをつくろう——言語処理系をつくりながら学ぶコンパイルと実行環境の仕組み』(中文翻译版《自制编译器》正在进行中,预计年内能上市)
其中第二本书我在这里有简单介绍:
学习编程语言与编译优化的一个书单这两本书,前者介绍的是一个完整但简单得多的C语言编译器LCC,有完整的编译流程,并且讲解了一些优化;后者介绍的是一个简单的用Java实现的简化版C的编译器cbc,介绍了完整的编译+链接流程,用Java实现十分便于修改和调试。
前者更贴近现实,而后者更简单易懂,两者分别适合从不同角度切入编译原理的入门学习。
评论区有同学提到这本书:
Compiler in C - Allen Holub这是本老书了,作者很慷慨的把书本的电子版以及配套代码免费发布在了个人网站上(点上面的链接可以下载)。
这确实也是一本讲得很详细的入门书,也是图文并茂、平易近人的风格。有兴趣挖掘历史的话这本读读也是轻松有趣。
跟其它入门书一样,这本也是重前端轻后端的,优化部分简单略过;目标代码生成部分为了简单而实现了一个“虚拟机”,这“目标代码”其实还是C语言,可以进一步用别的C编译器来编译到机器码(嗯您没看错)——这里简化得可能有点过了,汇编/具体机器码/链接之类的话题都是略过。