
之前我也回答过类似的问题,但看到一些人对 UTF-16 有点魔怔了的态度,现在我在这个问题下重说一遍。
因为 UTF-16 更适合在内存中处理字符串,而 UTF-8 更适合传输和存储,以及 UTF-8 与 ASCII 二进制级的兼容带来了一些应用场景,所以他俩并不存在替代关系,都有自己的存在意义。
这个问题下的很多回答我难以苟同。以前我也觉得 UTF-16 缺点很多,但在理解越来越深入之后,我理解了 UTF-16 是一个优秀的折中方案。
我们列举一下 UTF-8 和 UTF-16 作为内存中字符串编码各自的利弊:
生态
UTF-8 字节级兼容 ASCII,更方便与使用 char * 的 C 库兼容(尤其是类 Unix 平台上很常见);UTF-16 字节级兼容 UCS2,Win32 API、Qt、ICU、Java、C#、JavaScript 等生态都以 UTF-16 作为首选字符串编码,因此同样拥有很多生态。就生态而言,两者可以说平分秋色。
I/O
UTF-8 是当前最流行的文本格式编码,内存中使用 UTF-8 在 I/O 时就不需要再转换编码,UTF-8 毫无疑问的具有压倒性优势。
内存占用
不同类型的字符以 UTF-8 编码时占用的内存大概是这样:
- ASCII 字符:1 字节
- 欧洲语言字符:2 字节
- 中日韩常用字符:3 字节
- Emoji/其他罕见字符:4 字节
而用 UTF-16 编码时大概这样:
- ASCII 字符/欧洲语言字符/中日韩常用字符:2 字节
- Emoji/其他罕见字符:4 字节
UTF-8 在存储以 ASCII 字符为主的字符串时内存占用更低,UTF-16 在存储以中日韩常用字符为主的字符串时内存占用更低。
由于通常编程语言要处理的 ASCII 字符串更多,所以一般来说 UTF-8 比 UTF-16 占用的内存更低。
不过,Java/JavaScript 现在又采用了一种改良方案:字符串 API 保持与 UTF-16 兼容,而字符串内部选择 Latin-1 或 UTF-16 存储数据,这使得内存占用变成这样:
- ASCII / 西欧语言字符:1 字节
- 其他欧洲语言字符/中日韩常用字符:2 字节
- Emoji:4 字节
这种混合方案在存储 ASCII 字符串时不再劣于 UTF-8,同时在存储西欧语言字符或者以中日韩常用字符为主的字符串时内存占用比 UTF-8 更低,总体来说和 UTF-8 也算平分秋色。
字符串操作
UTF-16 的一个比较重要的优点是,它很多情况下可以被当成定长字符串的近似物进行处理。
当我们对 Unicode 稍所了解的时候,我们可能会对这种用法有些嗤之以鼻,认为这太 unsound,毕竟 UTF-16 编码一个 Unicode Code Point 可能需要两个码元构成代理对才能表示,实际上是变长的。
但我们要知道,普通人认知中的字符也并不是 Code Point,而是 Unicode 的字素簇(Grapheme Clusters),或者叫用户可感字符(User-perceived characters)。
一个字素簇可以是一个或者一串 Unicode Code Point,比如字母 A 和组合变音符号 ◌̊(U+030A)放在一起能构成一个字符 Å,那怕用 UTF-32 去存储它也是两个 Code Point。
一个字素簇可能由十几个甚至更多 Code Point 串联而成,需要几十甚至几百字节,远不是现在的计算机通用寄存器能放下的,而且想要正确处理字素簇需要对 Unicode 有很深的认知。
追求健全当然好,但这个代价过大而收益不高,所以现实中程序员大多数时候依然需要自欺欺人地把 Code Unit 或者 Code Point 当成字符处理。
现在很多新语言为了健全而不允许随机访问字符串等的操作,逼迫用户用更繁琐但更正确的以 Code Point 为单元去处理代码。这确实解决了代理对的截断问题,但并没有解决字素簇的截断问题,一样会出现乱码、一个字变多个、吞掉文字的部分组件、字形错误、排版错误等等问题, 所以健全性上没有根本性的进步。
到这里,UTF-16 的伪定长的意义就好理解了。毕竟大家大部分时候都是在骗自己,用 UTF-16 假装 UCS2 就能在躺着享受定长字符串的便利的同时应付 99.99% 的场景,相比要努力的骗自己来说还是更舒服点。
而且就算不想躺平,都是处理 Code Point,UTF-16 依然比 UTF-8 容易得多。
UTF-8 是 1~4 个 Code Unit 的变长编码:
| First code point | Last code point | Byte 1 | Byte 2 | Byte 3 | Byte 4 |
|---|---|---|---|---|---|
| U+0000 | U+007F | 0xxxxxxx | |||
| U+0080 | U+07FF | 110xxxxx | 10xxxxxx | ||
| U+0800 | U+FFFF | 1110xxxx | 10xxxxxx | 10xxxxxx | |
| U+010000 | [b]U+10FFFF | 11110xxx | 10xxxxxx | 10xxxxxx | 10xxxxxx |
而 UTF-16 是 1~2 个 Code Unit 的变长编码:
| First code point | First code point | Bytes |
|---|---|---|
| U+0000 | U+FFFF | xxxx xxxx xxxx xxxx - yyyy yyyy yyyy yyyy |
| U+10000 | U+10FFFF | 1101 10yy yyyy yyyy - 1101 11xx xxxx xxxx |
我把 UTF-8 和 UTF-16 数组分别解码为 Code Points 的代码展示一下(已简化错误处理),看长度就知道它们处理难度有多大区别了。
这是 UTF-16:

下面这几个工具方法都很通用,可以轻松的封装进一个工具类里,核心的解码代码随便
至于 UTF-8……
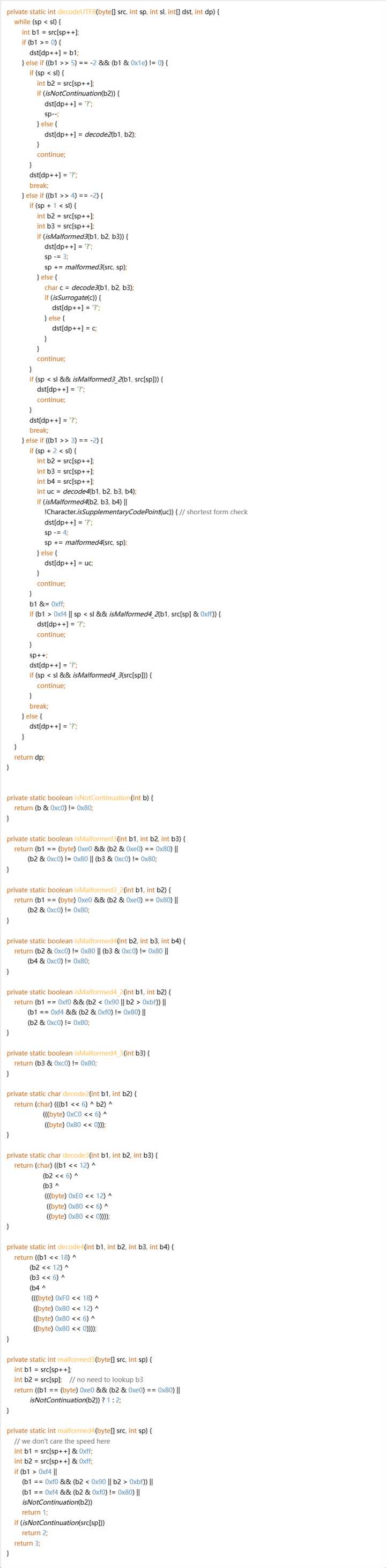
显而易见,UTF-8 和 UTF-16 的复杂程度完全不在一个级别,完全不是一句“同样是变长编码”就能概括的。当然大部分时候我们都会使用封装好的库来处理,但在不得不手写一些操作的时候,UTF-16 处理起来可以说轻松愉快,UTF-8 则是对着抄都怕抄错。
如果再要进一步,真正认真去处理字素簇,那 UTF-8/UTF-16/UTF-32 之间也没有什么区别,毕竟这个复杂程度已经不是可以考虑手写的程度,都不得不用那么几个由领域专家封装好的库来处理。
综合来看,虽然 UTF-16 的存在背后确实有复杂的历史问题,如果能完全抛弃历史包袱,我们能有更好的选择(比如 Python 那样底层自动选择 Latin-1/UCS2/UCS4),但就现状而言 UTF-16 也并非像一些人所认为的那样一无是处。